learning generated abstractions
For this experiment, I only had one technical idea to execute: generating visuals procedurally and feed that into a generative model. Then, press play.
Instead of training a model on publicaly available images, it learned to model various shapes of color. For the present iteration, 256x256 images were computed using various array mangling methods and (really basic) color theory principles. They were then fed into a GAN architecture with convolutional layers, namely a DCGAN.
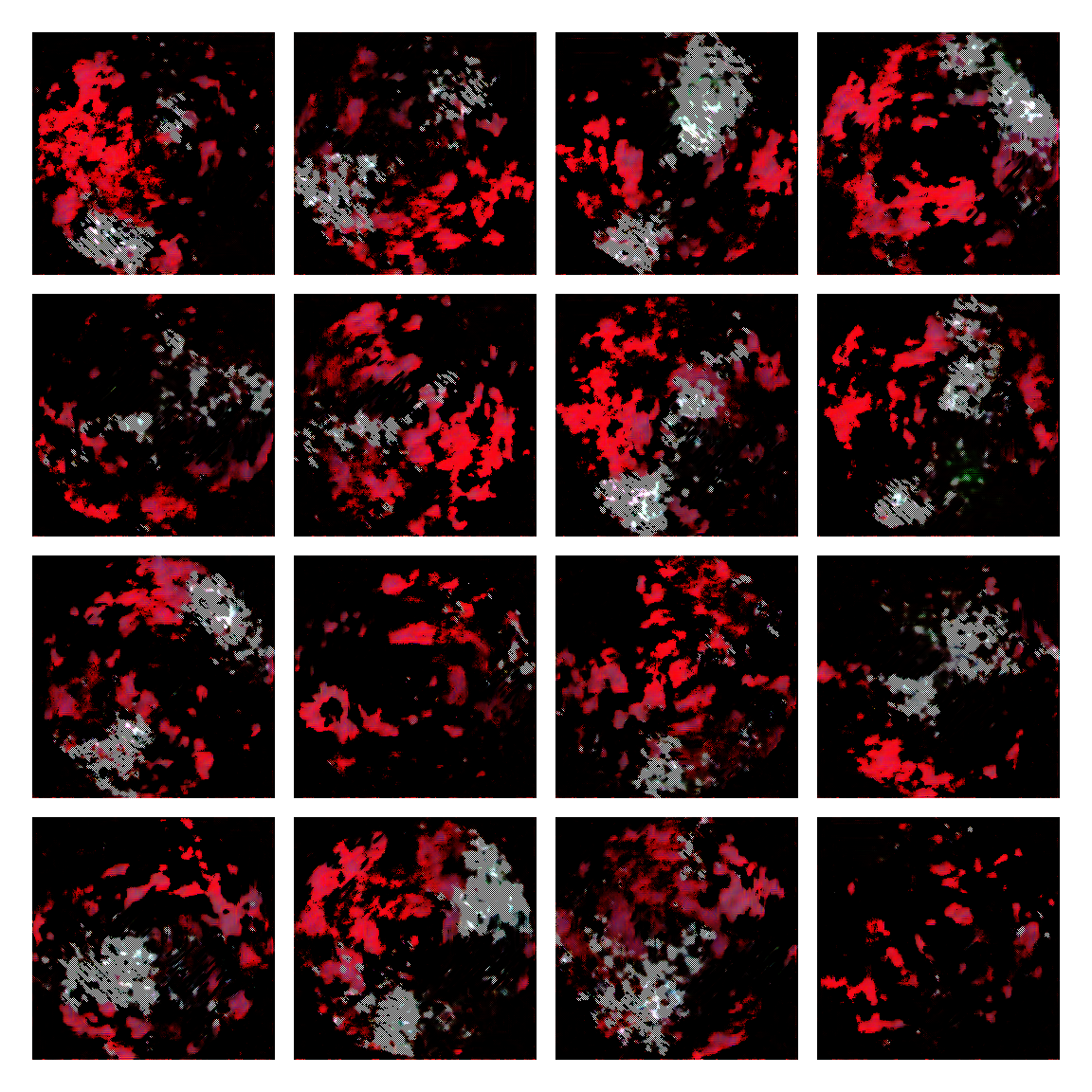
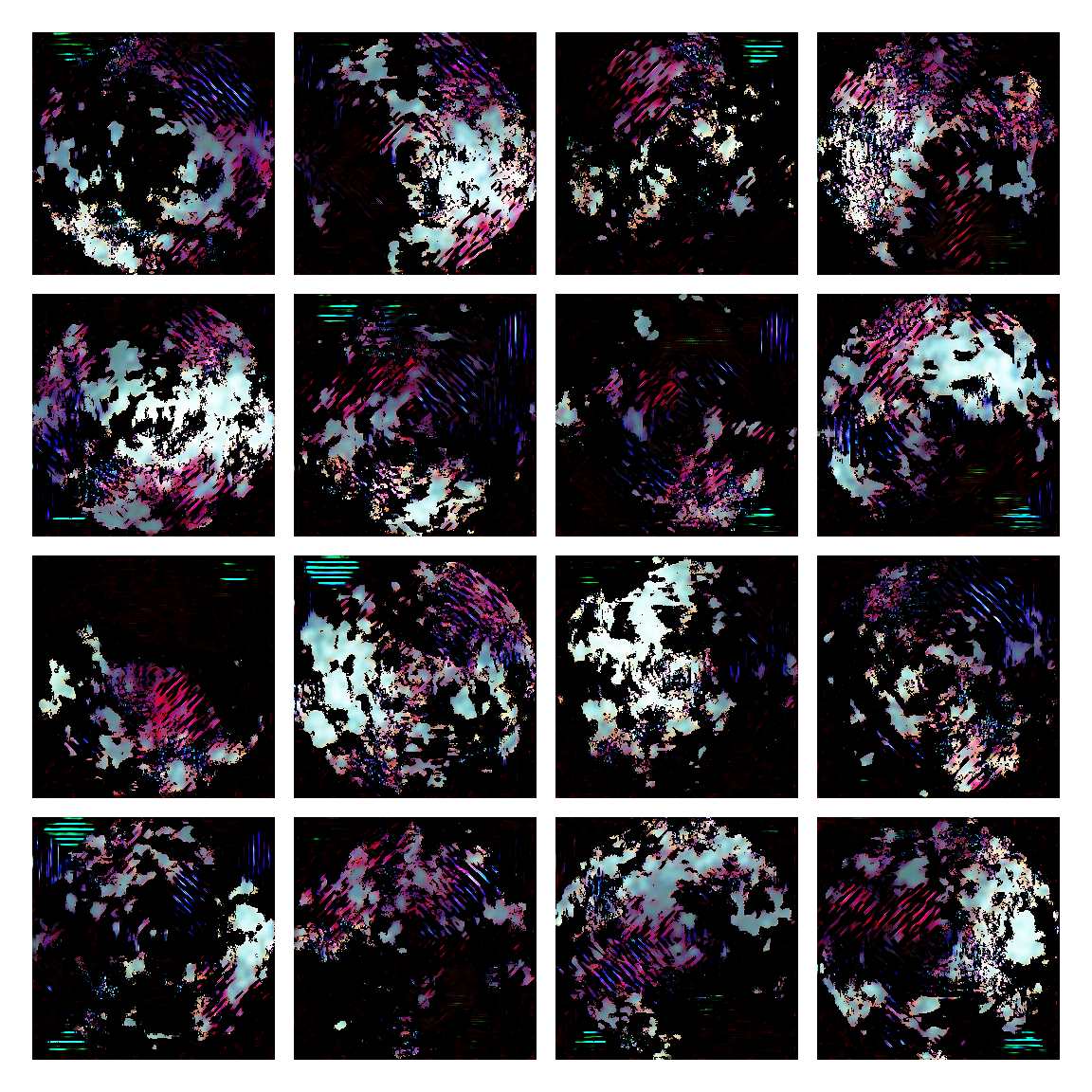
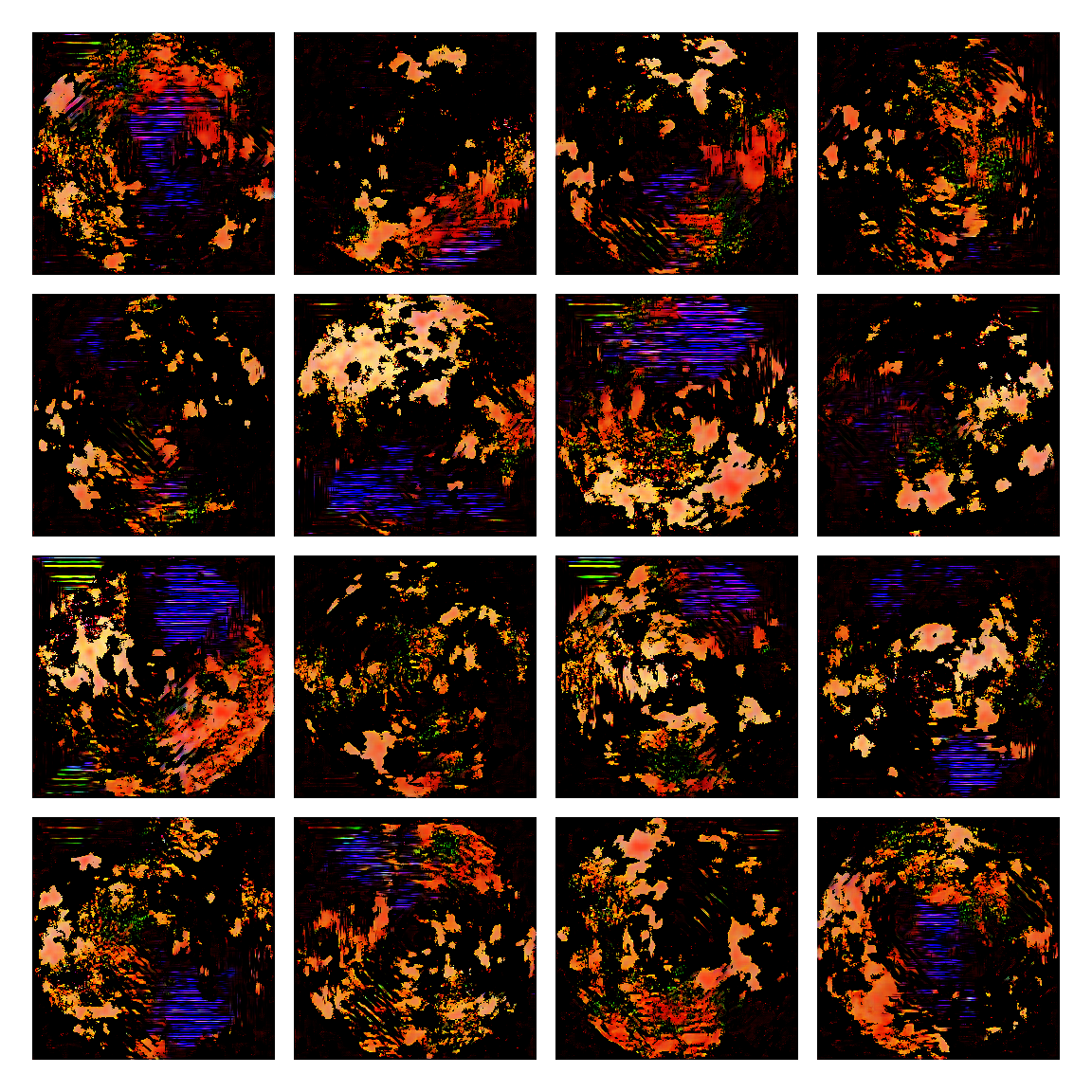
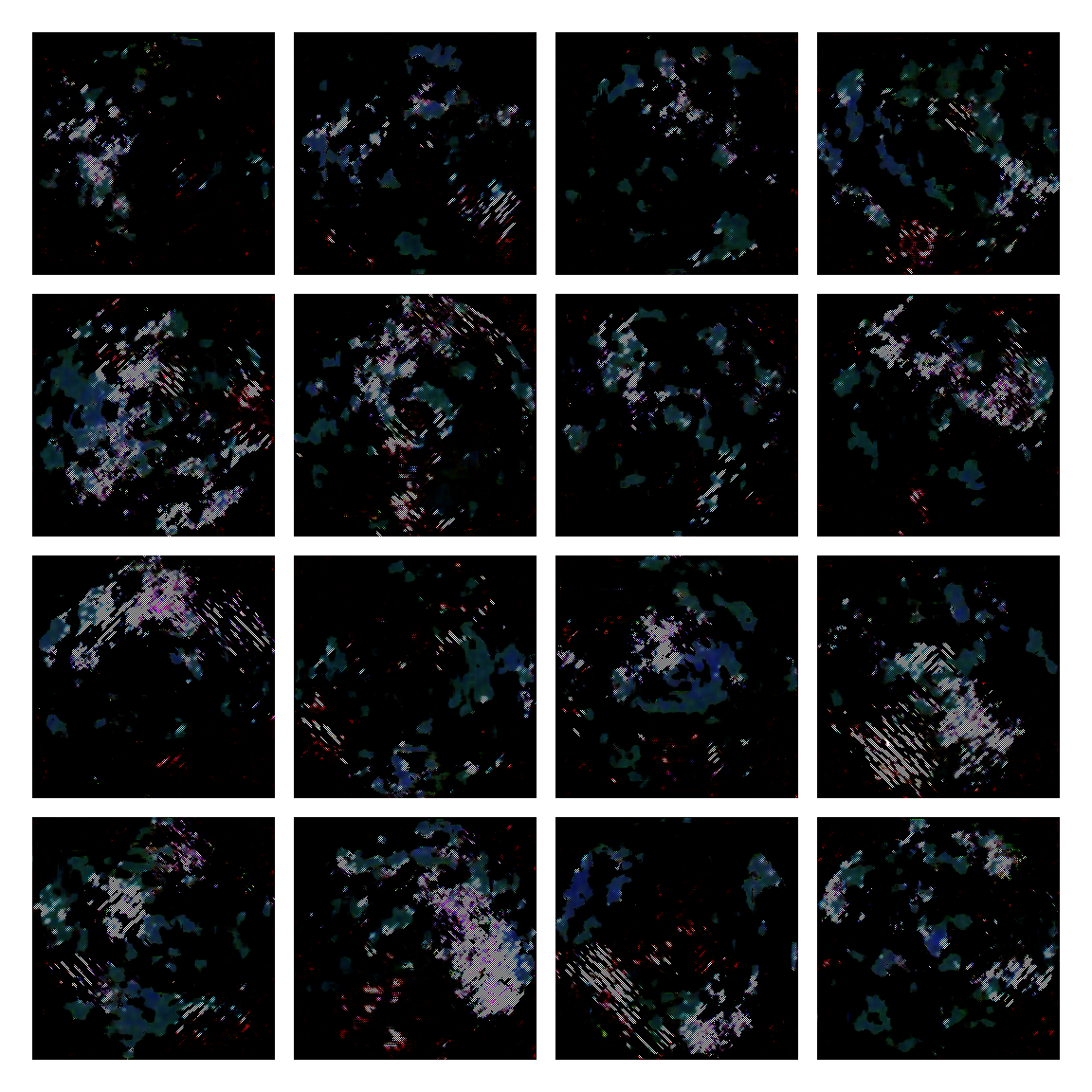
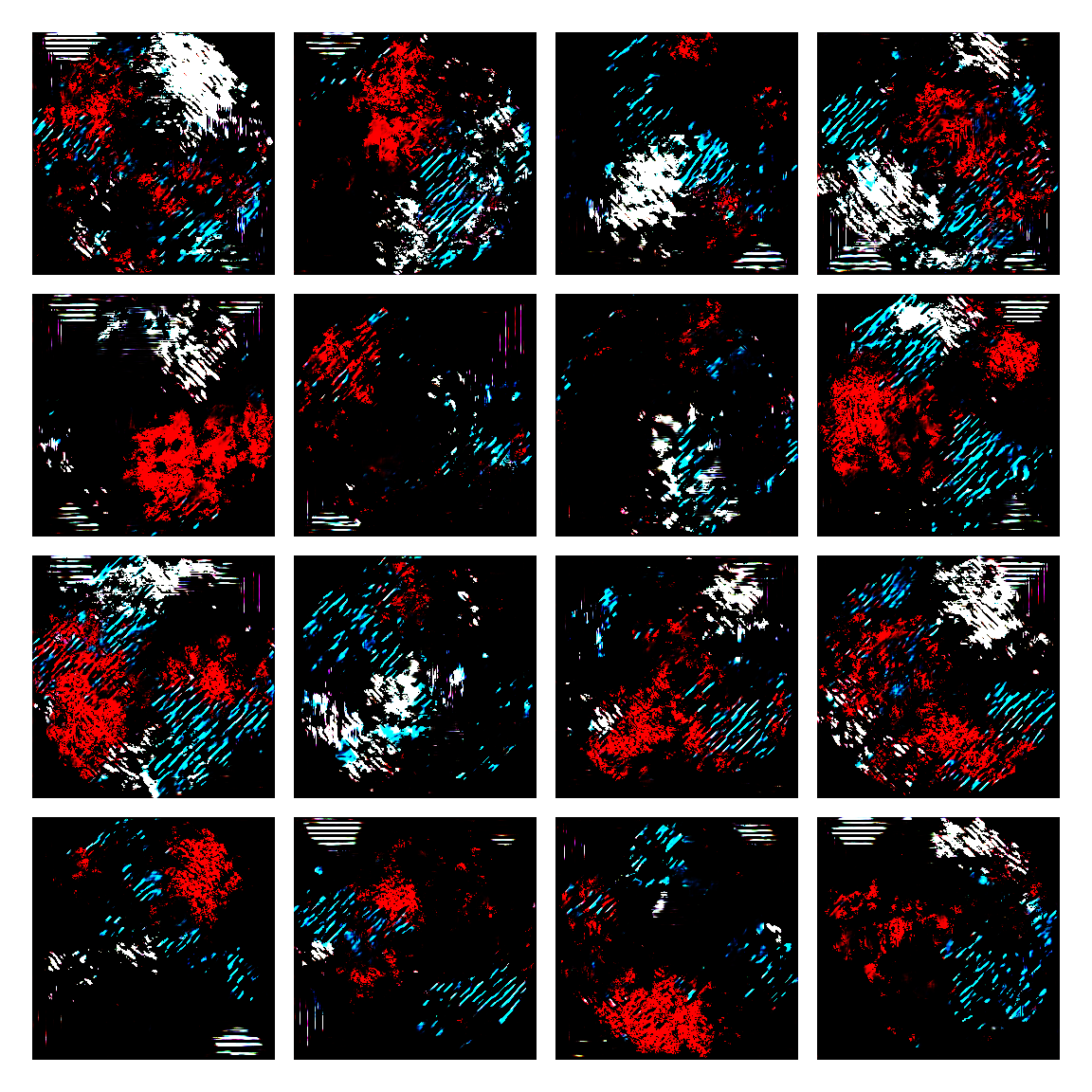
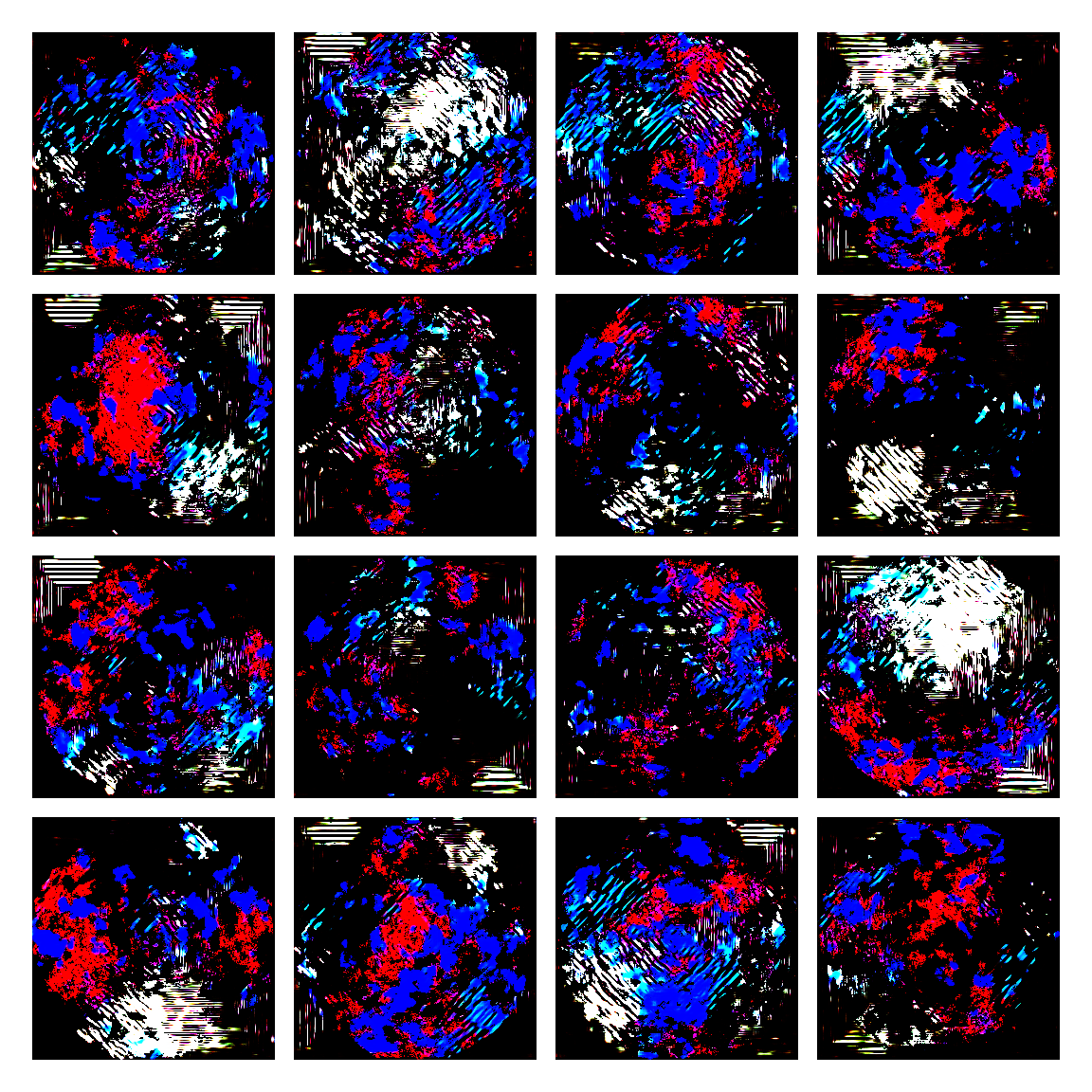
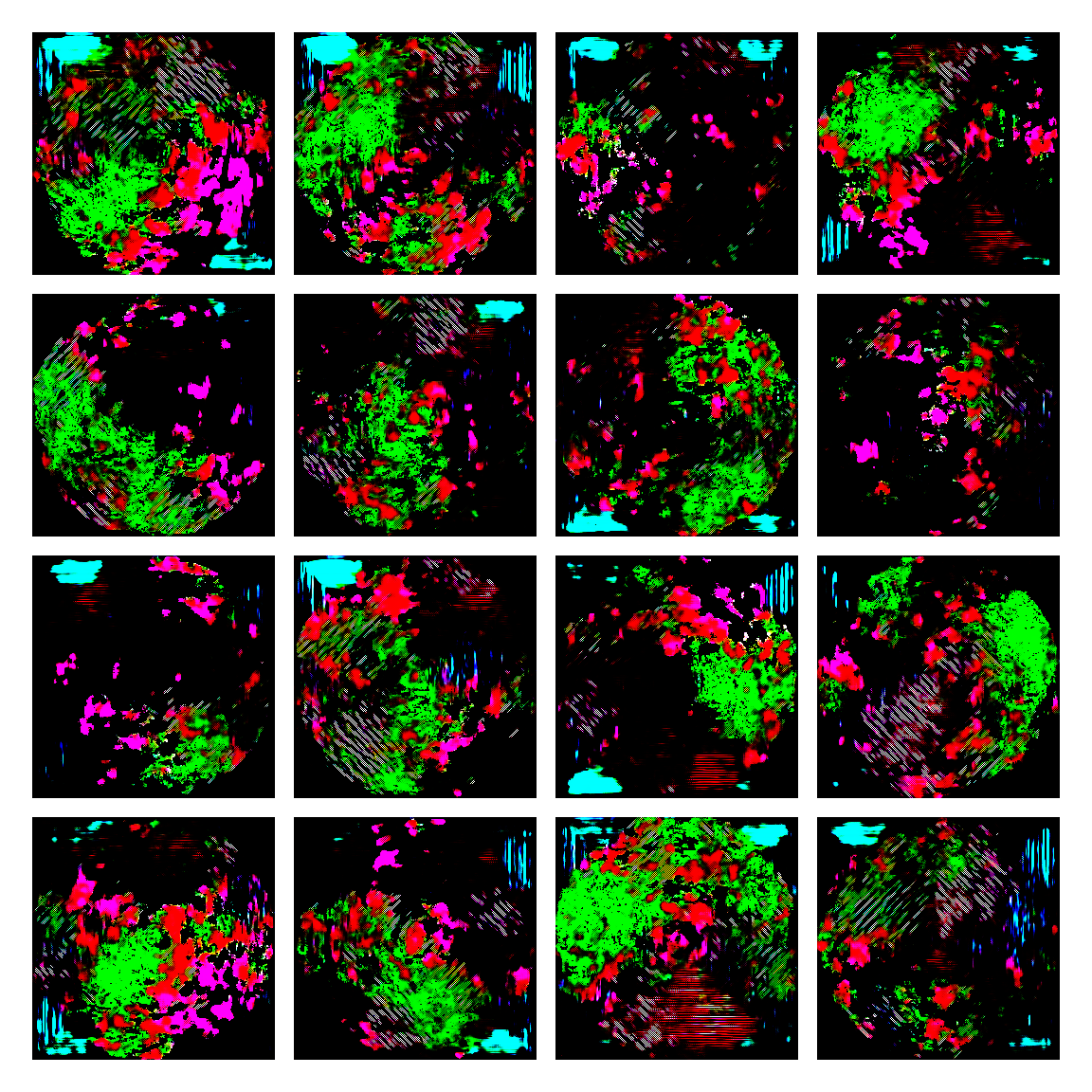
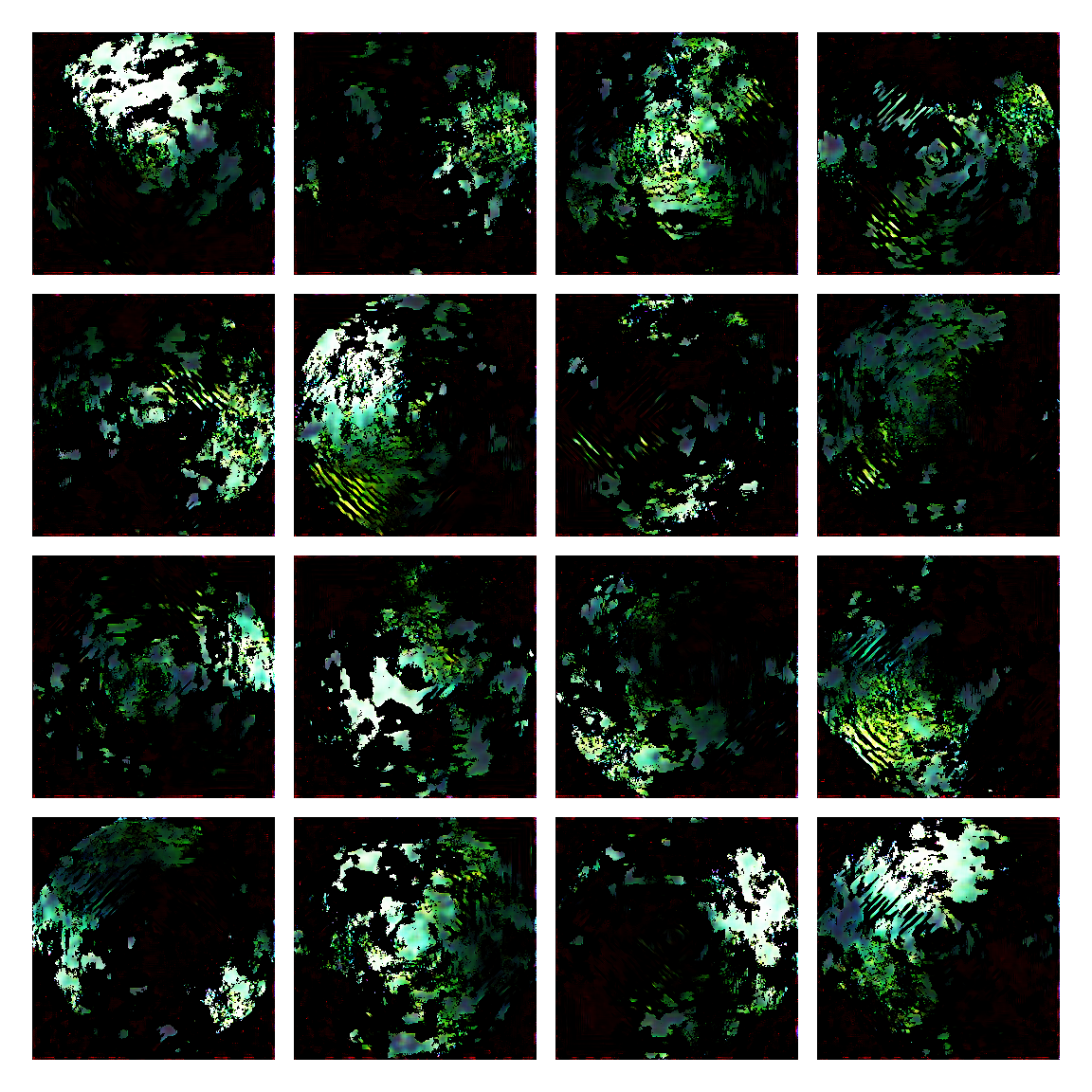
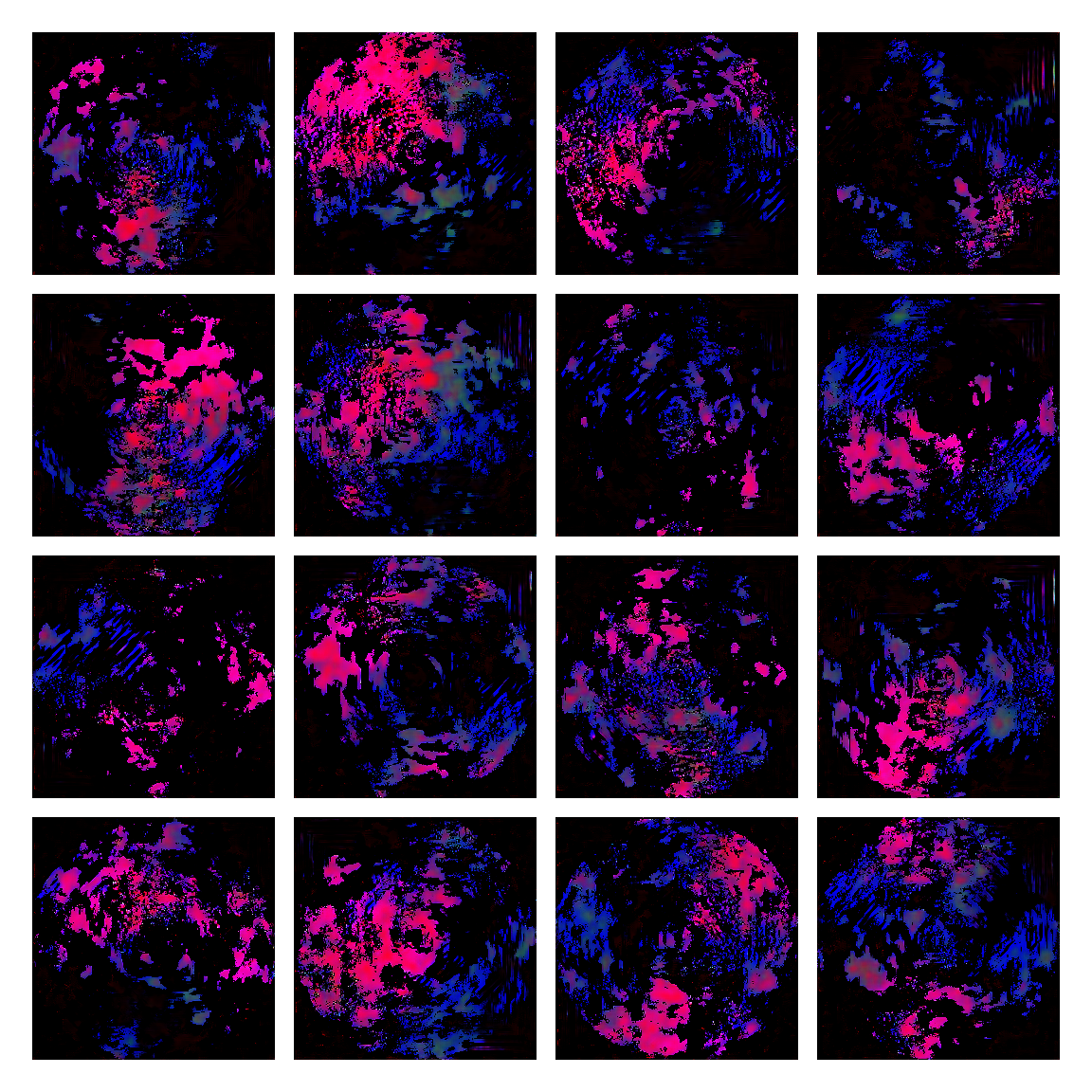
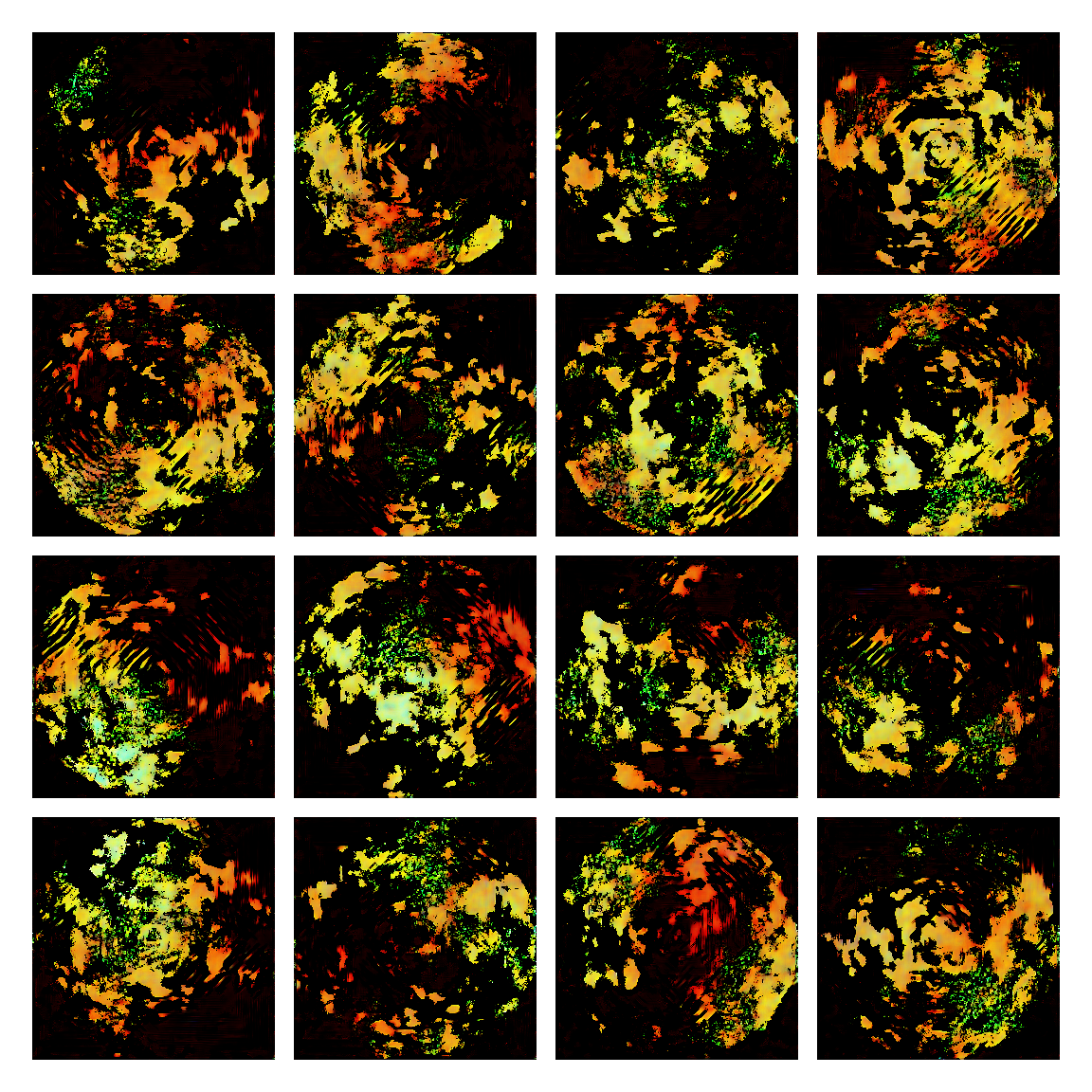
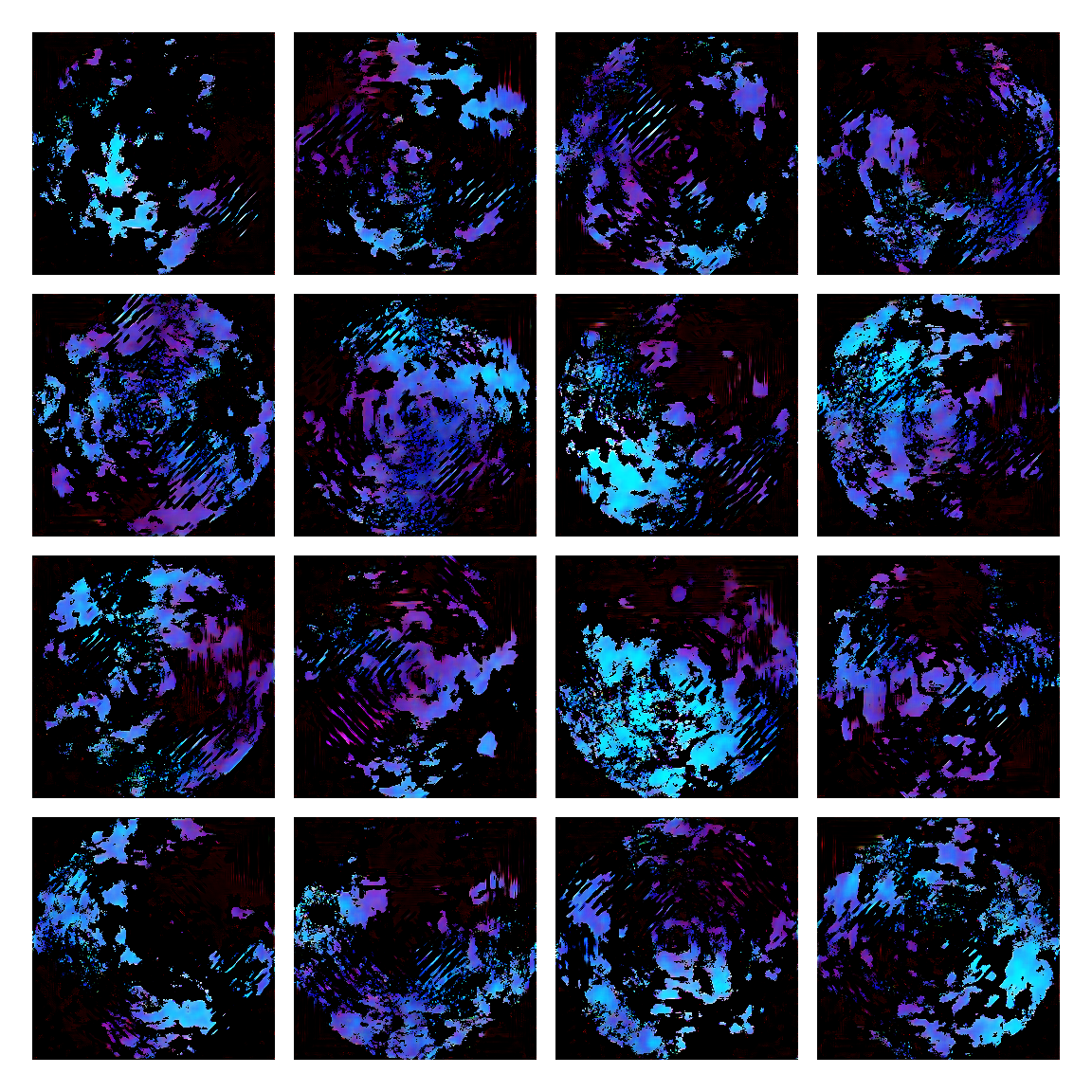
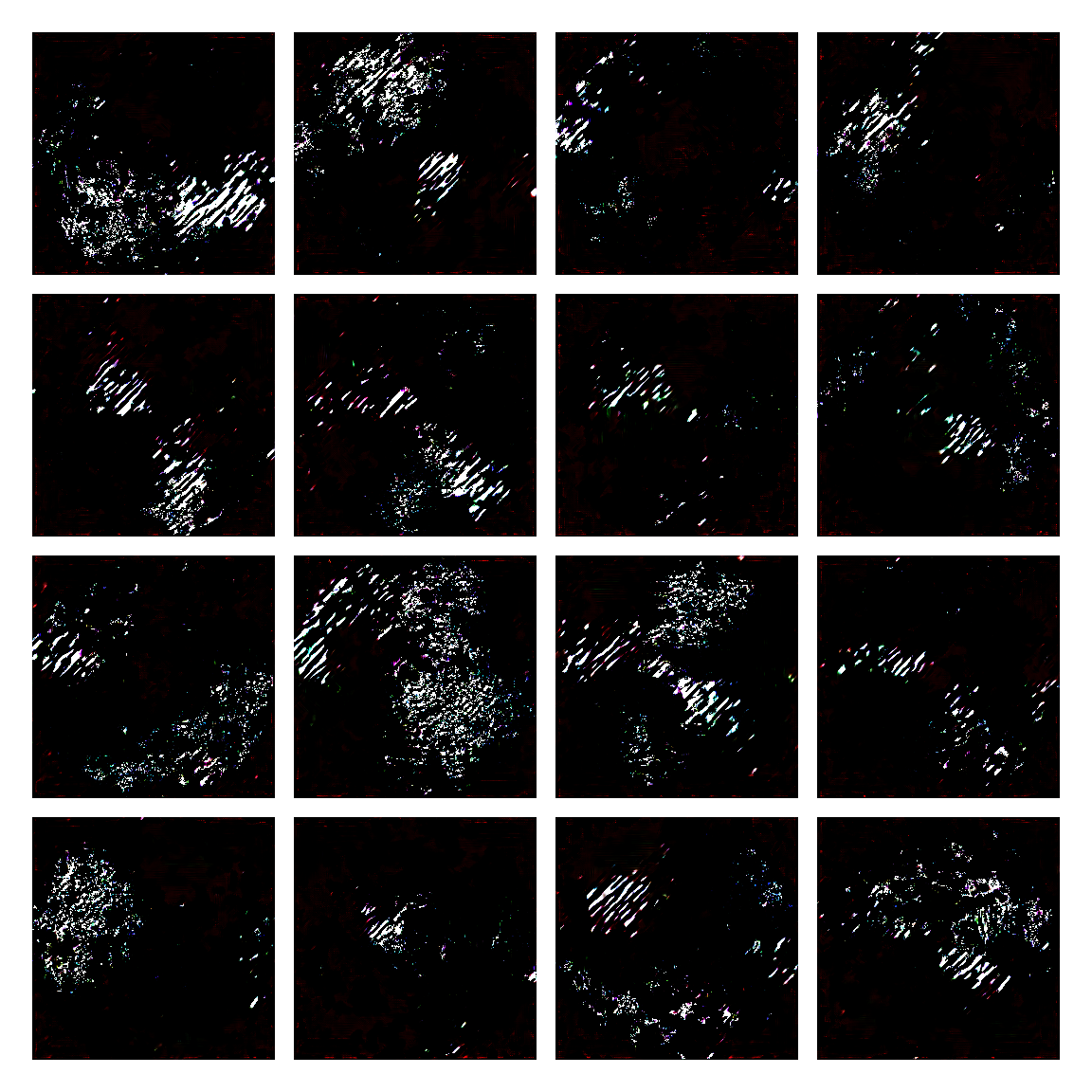
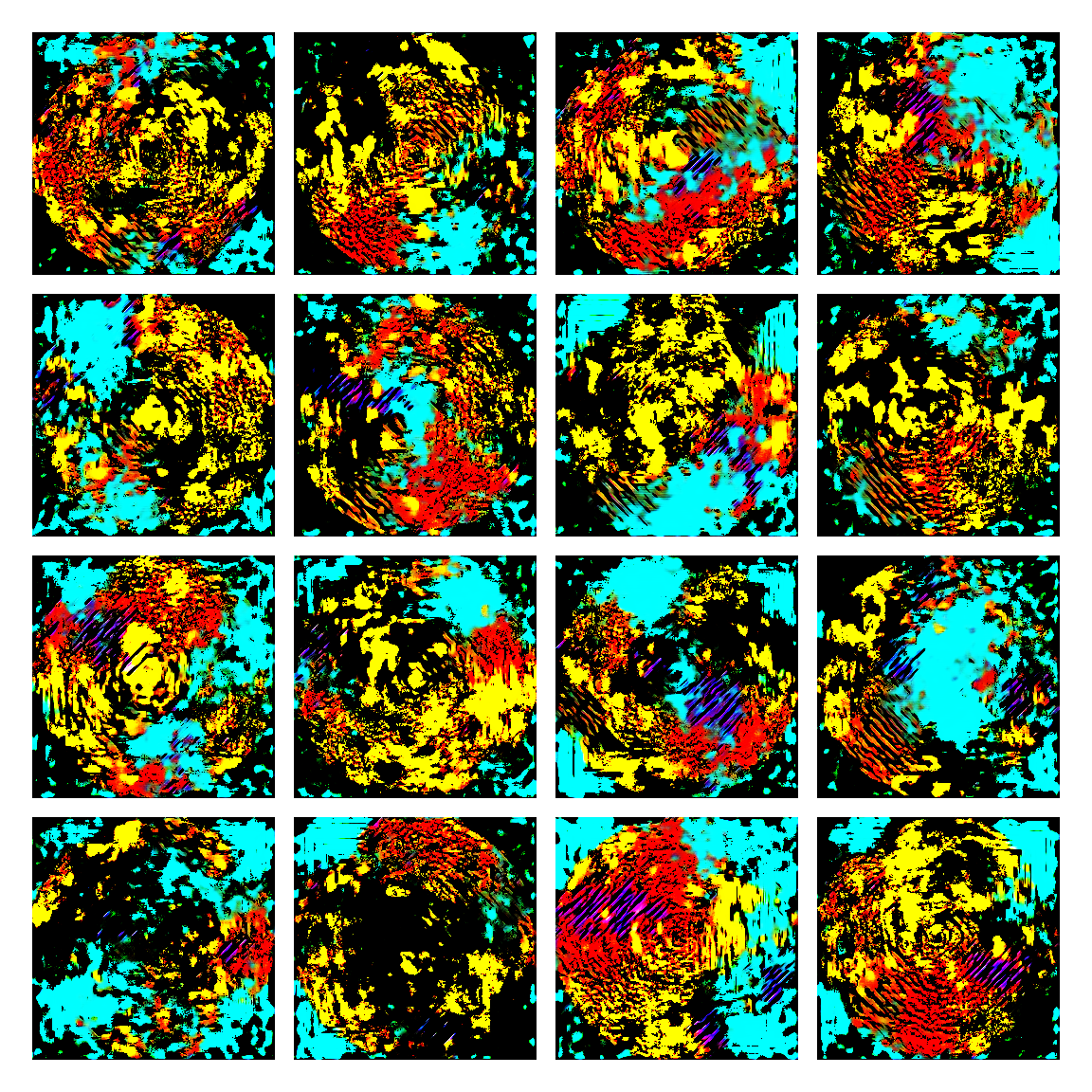
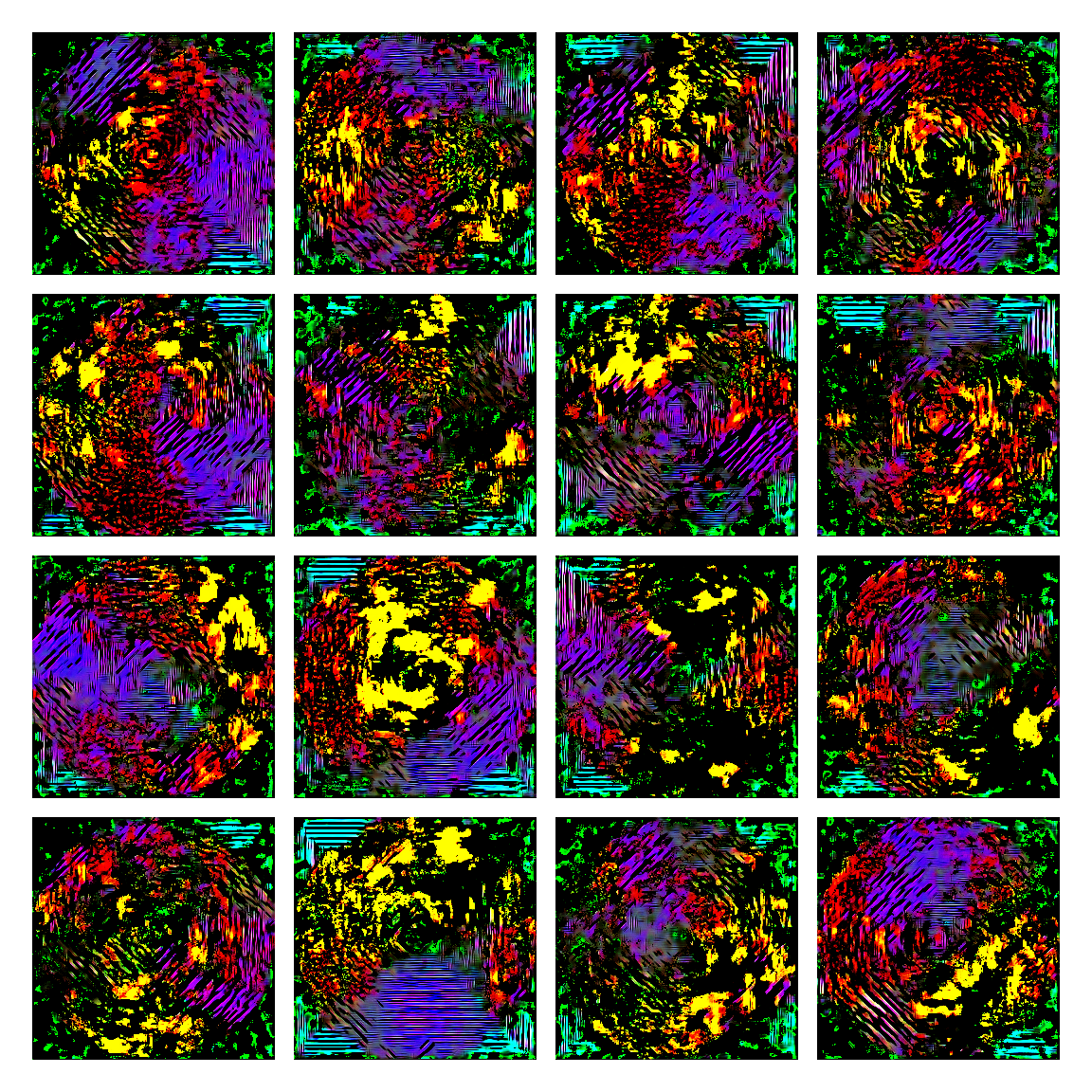
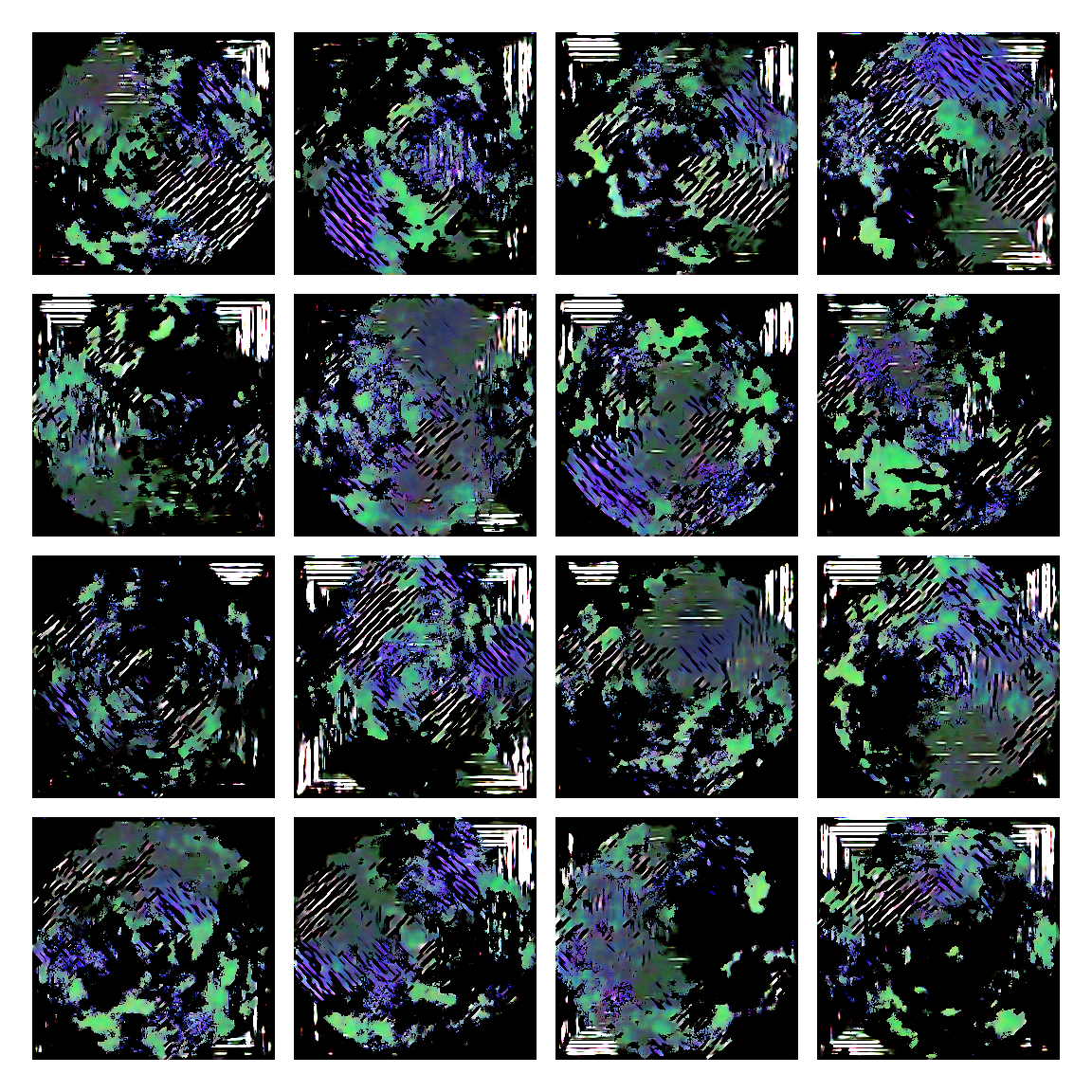
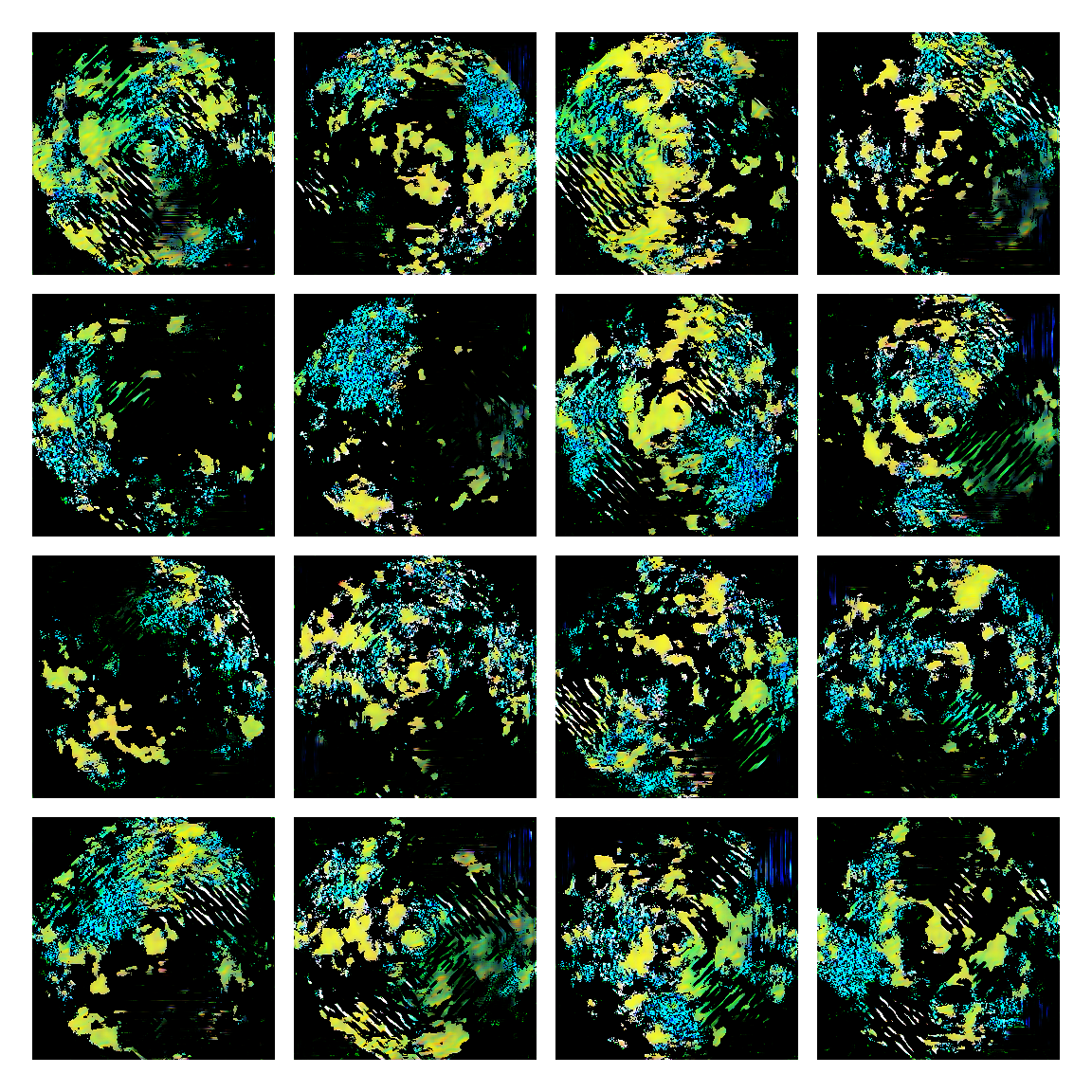
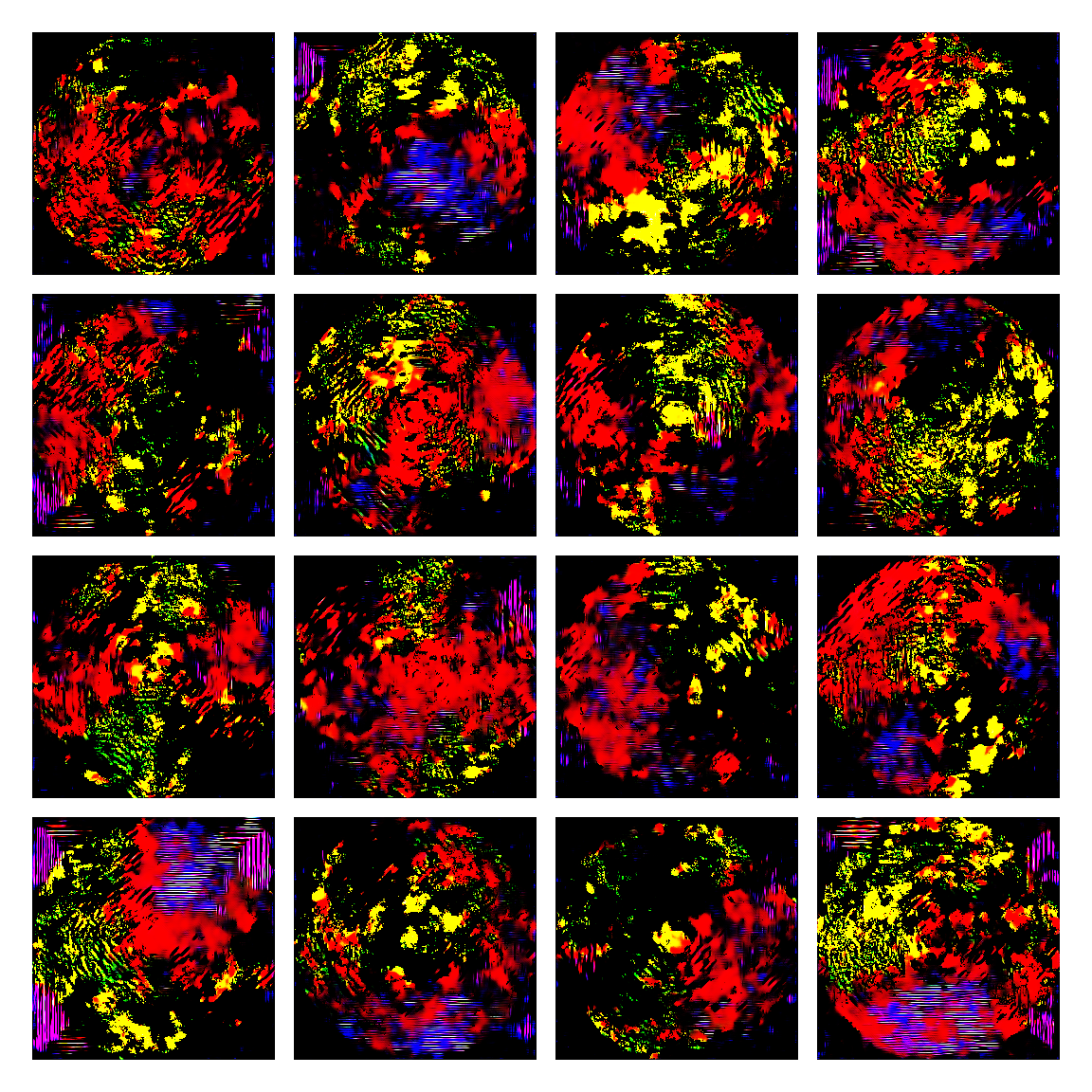
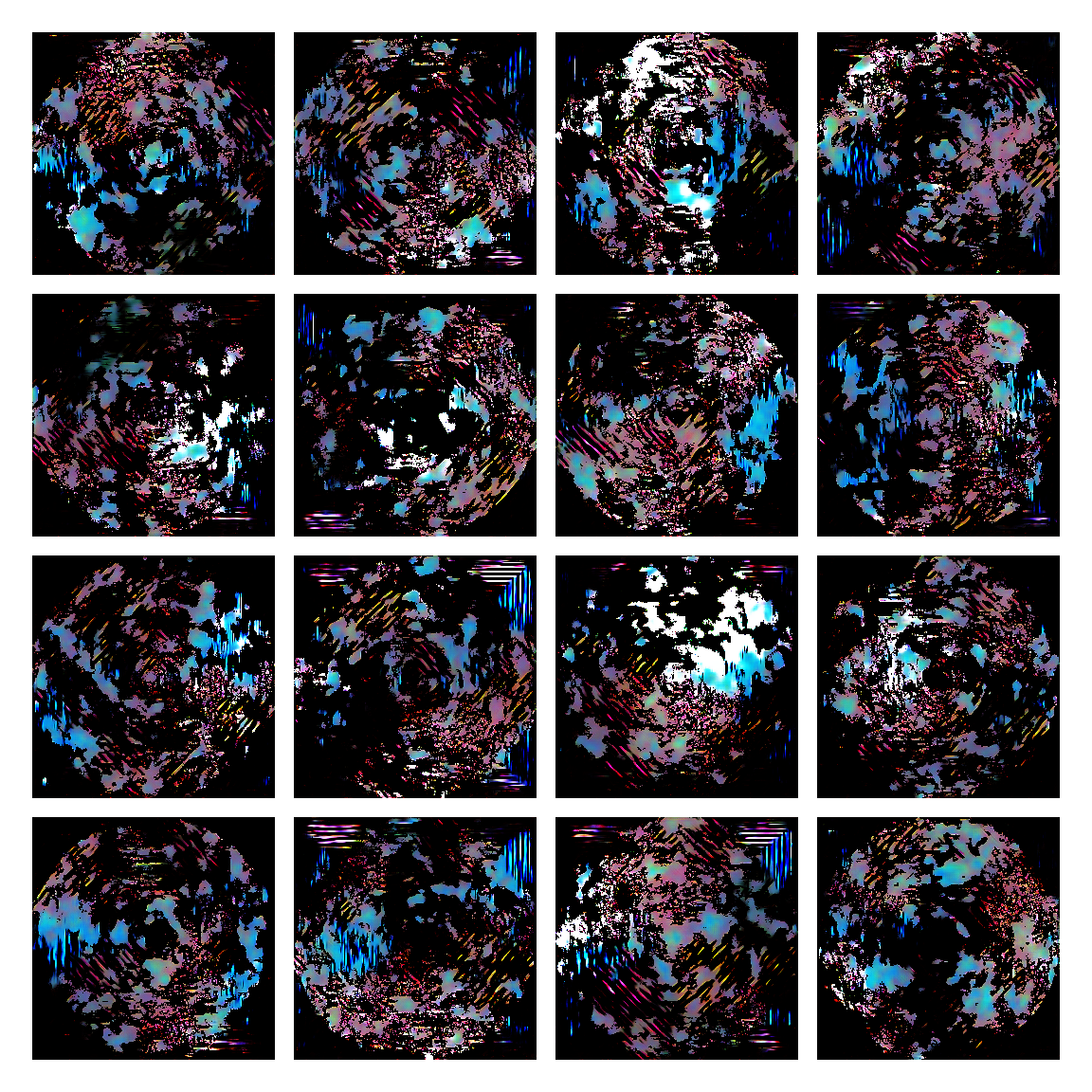
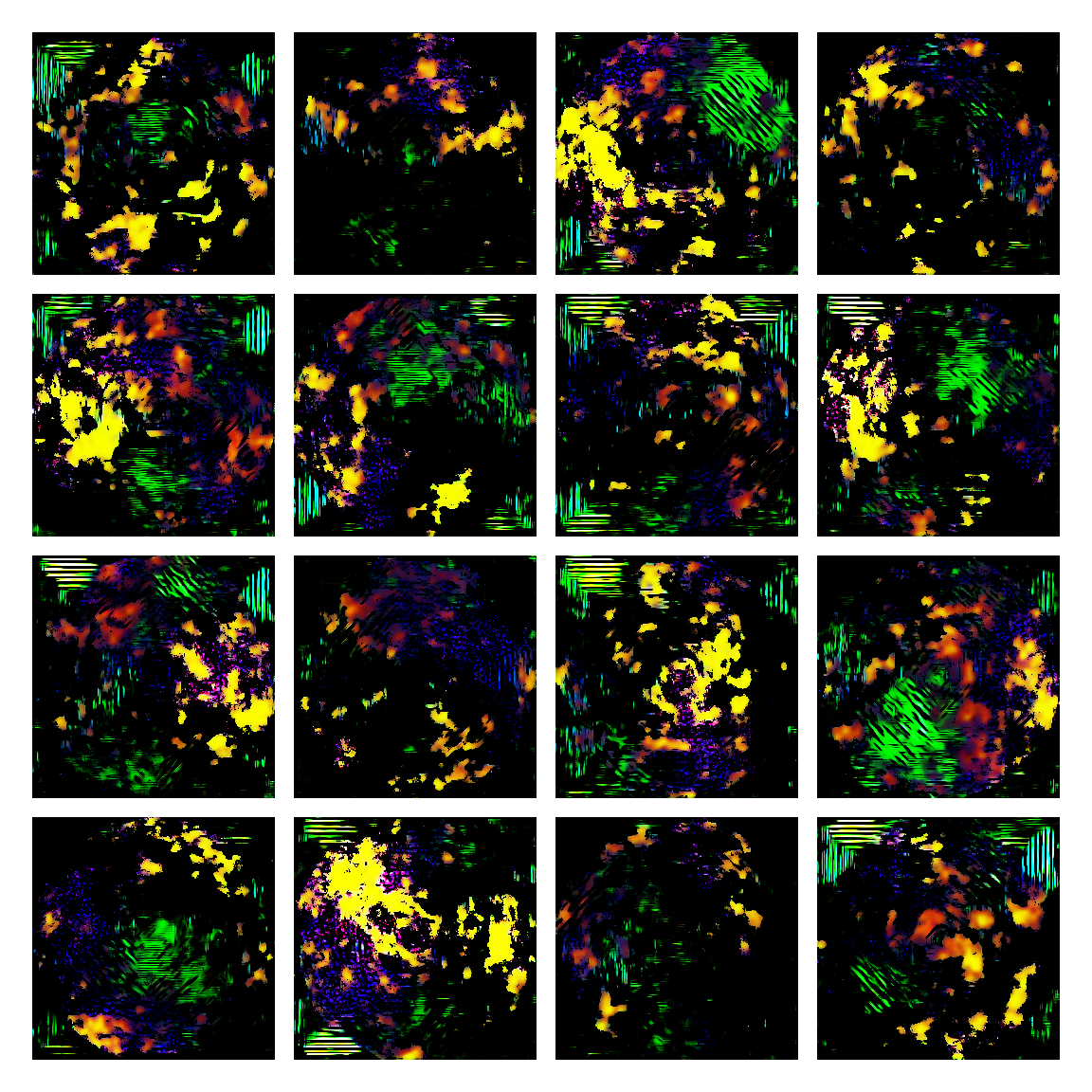
I honestly didn’t know where this would led me when I started, but I think the current results are interesting enough to share. This is a snapshot of some generated images I sampled from the model while training it. I then made mosaic-like collages for display.
The model training didn’t converge correctly, and instead started oscillating between different modes. Not sure of the reasons why, but I suspect it’s due to the input distribution being too sparse, or simply the model architecture was not the right one. I was actually quite glad this happened, since it generated images with a distinctive aesthetic from the input, without the model gradients being smashed to zero in this dark and vast multivariate land. It averaged out the initial image generating procedures.
Original excerpt:
This project, which might never end, aims at exploring properties of closed but continously evolving virtual worlds. When we program a piece of software to learn simple but purely virtual representations, what happens in the middle of the process?





For those interested, the architecture goes as follow using Keras:
Discriminator Model
- Total params: 669,665
- Trainable params: 668,769
- Non-trainable params: 896
| Layer | (type) | Output Shape | Param # |
|---|---|---|---|
| conv2d | (Conv2D) | (None, 128, 128, 32) | 1568 |
| leaky_re_lu | (LeakyReLU) | (None, 128, 128, 32) | 0 |
| dropout | (Dropout) | (None, 128, 128, 32) | 0 |
| conv2d_1 | (Conv2D) | (None, 64, 64, 64) | 18496 |
| zero_padding2d | (ZeroPadding2D) | (None, 65, 65, 64) | 0 |
| batch_normalization | (BatchNormalization) | (None, 65, 65, 64) | 256 |
| leaky_re_lu_1 | (LeakyReLU) | (None, 65, 65, 64) | 0 |
| dropout_1 | (Dropout) | (None, 65, 65, 64) | 0 |
| conv2d_2 | (Conv2D) | (None, 33, 33, 128) | 73856 |
| batch_normalization_1 | (BatchNormalization) | (None, 33, 33, 128) | 512 |
| leaky_re_lu_2 | (LeakyReLU) | (None, 33, 33, 128) | 0 |
| dropout_2 | (Dropout) | (None, 33, 33, 128) | 0 |
| conv2d_3 | (Conv2D) | (None, 33, 33, 256) | 295168 |
| batch_normalization_2 | (BatchNormalization) | (None, 33, 33, 256) | 1024 |
| leaky_re_lu_3 | (LeakyReLU) | (None, 33, 33, 256) | 0 |
| dropout_3 | (Dropout) | (None, 33, 33, 256) | 0 |
| flatten | (Flatten) | (None, 278784) | 0 |
| dense | (Dense) | (None, 1) | 278785 |
Generator Model
- Total params: 106,802,435
- Trainable params: 106,801,667
- Non-trainable params: 768
| Layer | (type) | Output Shape | Param # |
|---|---|---|---|
| dense_1 | (Dense) | (None, 1048576) | 105906176 |
| reshape | (Reshape) | (None, 64, 64, 256) | 0 |
| up_sampling2d | (UpSampling2D) | (None, 128, 128, 256) | 0 |
| conv2d_4 | (Conv2D) | (None, 128, 128, 256) | 590080 |
| zero_padding2d | (BatchNormalization) | (None, 128, 128, 256) | 1024 |
| batch_normalization_3 | (Activation) | (None, 128, 128, 256) | 0 |
| activation | (UpSampling2D) | (None, 256, 256, 256) | 0 |
| up_sampling2d_1 | (Conv2D) | (None, 256, 256, 128) | 295040 |
| conv2d_5 | (BatchNormalization) | (None, 256, 256, 128) | 512 |
| batch_normalization_4 | (Activation) | (None, 256, 256, 128) | 0 |
| conv2d_6 | (Conv2D) | (None, 256, 256, 3) | 9603 |
| activation_2 | (Activation) | (None, 256, 256, 3) | 0 |